







From Tissue Engineering to the Adult Industry

If you're a DevOps working with adult projects, your typical "adult content" might look something like this.
One of the most traditional topics nowadays is the unexpected career shifts from various professions to IT and vice versa. I had this fantastic colleague – a professional butcher by training. He sets up monitoring systems like a pro and can defend his point of view convincingly. His education certainly plays a part in that.
You can also include me among those with a peculiar career switch. I originally started as a doctor, who then veered towards fundamental science and tissue engineering. All those diversions with stem cells, growing organs in bioreactors, and other atypical experimental tasks. And then, out of the blue, I was invited for an interview at a large telecom company... Long story short, I found myself as a DevOps in a company dealing with complex projects, some of which are about adult videos. Yes, those very special educational movies for adults that drive progress, with petabytes of traffic, millions of users, and all the other joys.
Here’s how it works for us - there comes a time in a business when they realize, that's it. We've arrived. The infrastructure is working, everything seems fine, but it's built on hacks carefully laid by three generations of employees. There’s no documentation, nobody remembers how it all works. If a server dies, resurrecting it would be a miracle.
And that's usually the moment when we, the WiseOps team, come in. We start dissecting every nut and bolt of the archaeological layers of code, architecture, and business logic. We already have dozens of clients, three of whom are in the video content business.
Let's dive deeper, and I'll try to show you what this whole industry looks like through the eyes of a doctor/bio-engineer/DevOps.
You can also include me among those with a peculiar career switch. I originally started as a doctor, who then veered towards fundamental science and tissue engineering. All those diversions with stem cells, growing organs in bioreactors, and other atypical experimental tasks. And then, out of the blue, I was invited for an interview at a large telecom company... Long story short, I found myself as a DevOps in a company dealing with complex projects, some of which are about adult videos. Yes, those very special educational movies for adults that drive progress, with petabytes of traffic, millions of users, and all the other joys.
Here’s how it works for us - there comes a time in a business when they realize, that's it. We've arrived. The infrastructure is working, everything seems fine, but it's built on hacks carefully laid by three generations of employees. There’s no documentation, nobody remembers how it all works. If a server dies, resurrecting it would be a miracle.
And that's usually the moment when we, the WiseOps team, come in. We start dissecting every nut and bolt of the archaeological layers of code, architecture, and business logic. We already have dozens of clients, three of whom are in the video content business.
Let's dive deeper, and I'll try to show you what this whole industry looks like through the eyes of a doctor/bio-engineer/DevOps.
A scientific background helps
In the first few months after changing professions, I had to learn even more intensely than before my exam in operative surgery, which was a quest in itself, believe me. Overall, this is inevitable if you take 12 years of primary professional education with postgraduate studies, a doctoral program, and ceremoniously scrap an unfinished dissertation. This was an incredibly cool experience that consistently helps me in life, but I realized the importance of acknowledging losses in time. This is where you encounter the typical cognitive bias - the sunk cost fallacy. You could view all the years spent on “leveling up a character in a different branch” as useless, or you could try to utilize this experience from another angle.

Experiment in process - shutting down an entire region
I quickly got the feeling that with the right approach, I was still engaged in the same scientific activity, but with different tasks. The key approach in science sounds something like this:
Another aspect that turned out to be extremely relevant, a standard in scientific research but not always used in IT, is that experiments should be both positive and negative.
For example, the task is to test the impact of a new API version on one of the subsystems to ensure its functionality.
The incorrect approach goes like this:
- Develop a hypothesis
- Honestly devise a method that disproves it
- Conduct experiments
- Present your findings with a poster at a conference
- How to decompose the load into individual bottlenecks?
- Can a unified model describe the ideal ratio of the viper to the hedgehog cores in vCPU of Sphinx nodes and the RAM volume on caching servers?
- Does it make sense to add cache beyond a certain threshold, or does it become saturated?
Another aspect that turned out to be extremely relevant, a standard in scientific research but not always used in IT, is that experiments should be both positive and negative.
For example, the task is to test the impact of a new API version on one of the subsystems to ensure its functionality.
The incorrect approach goes like this:
- Update the API code in the tested service's environment.
- Make sure everything works.
- Celebrate a successful deployment.
- Perform all the steps from the incorrect one.
- Disable/break the API to ensure that the system stops functioning.
Monitoring crashes louder than usual
In the special video industry, a DevOps does pretty much the same things, but with more fun, higher loads, and unexpected tasks. When your client's traffic starts exceeding the petabyte mark, many familiar approaches begin to work differently. For instance, you might suddenly find that due to a combination of factors and a badly-timed loss of connectivity between data centers, hundreds of instances start flooding your Graylog with complaints that they can't sense the API – in gigabytes. Then follows a whole cascade:
- Datadog, an external cloud monitoring system, starts saving its instances, selectively limiting the bandwidth of requests to its API. Monitoring begins to lag joyfully, responding to everything with a significant delay. The on-call tries to silence active alerts, and Datadog thoughtfully puts requests on mute in a long queue.
- Thousands of emails from various bots, Graylog, and monitoring systems pour into all messengers. The desktop sound just gets turned off because the quiet single clicks about new messages turn into the continuous crackle of a dosimeter in an active reactor zone.
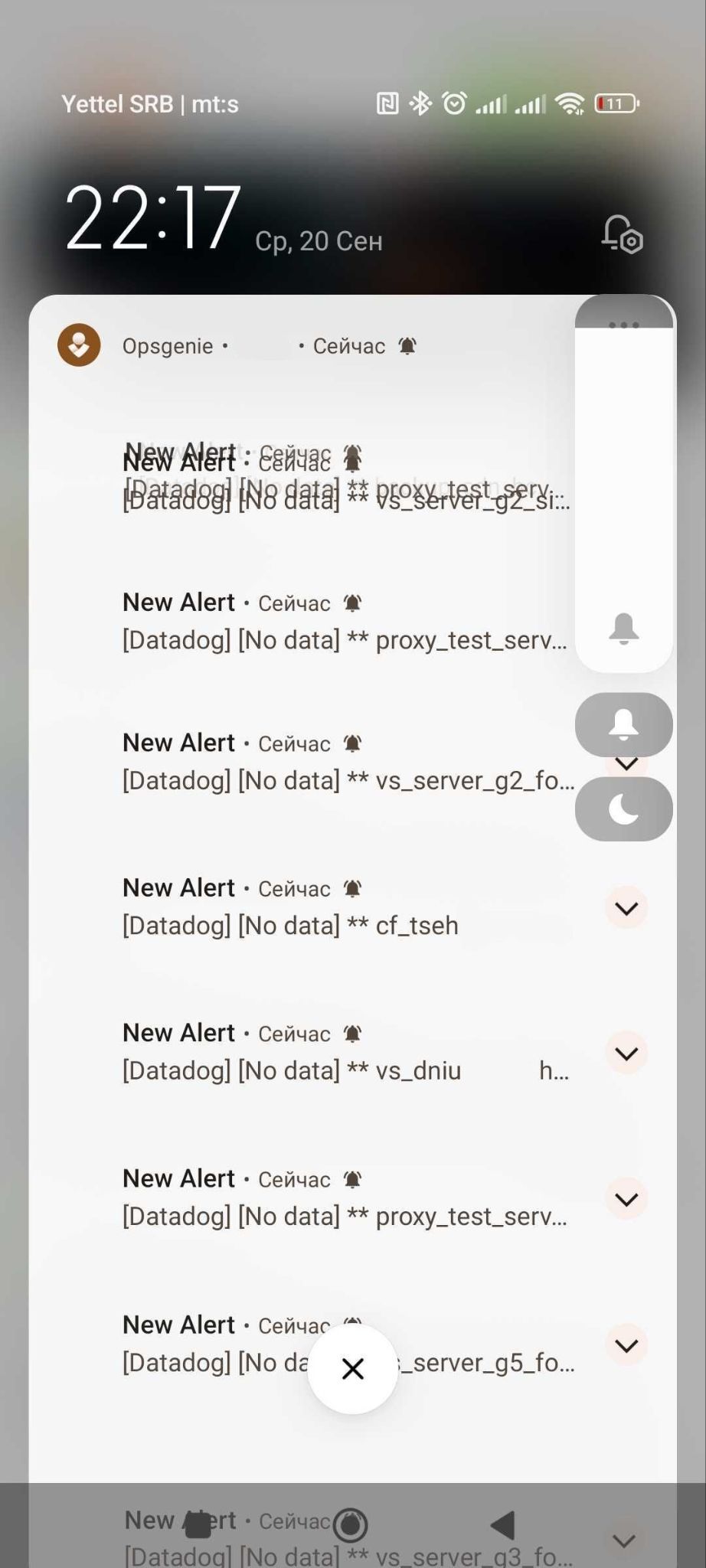
I never thought a phone could be bricked by thousands of pushes
In short, I ended up with 3,500 push messages from the monitoring system. Any attempt to silence it was futile, as the top part of the screen was unresponsive due to multiple pushes arriving every second. The app controls the volume and ensures that the siren goes off for each incoming alert, even if the user tries to turn off the sound.
In reality, one of the probe nodes, which checks the HTTP endpoints' operability, simply lost connectivity and cheerfully sent a batch of messages to Datadog, claiming several data centers with hundreds of endpoints had vanished. Possibly a meteorite. Monitoring there is specific, with alerts for each of the hundreds of existing connections. We eventually revised our alert notification system. Thanks to this unexpected load testing.
In reality, one of the probe nodes, which checks the HTTP endpoints' operability, simply lost connectivity and cheerfully sent a batch of messages to Datadog, claiming several data centers with hundreds of endpoints had vanished. Possibly a meteorite. Monitoring there is specific, with alerts for each of the hundreds of existing connections. We eventually revised our alert notification system. Thanks to this unexpected load testing.
Clients Complain About Shaky Camera
Unlike standard services, adult resources are subject not only to DMCA requirements but also a range of other restrictions. User complaints about seeing themselves in a video they didn't consent to must be addressed within a few hours. Moreover, complaints can come through dozens of channels - CloudFlare, domain registrars, site feedback, infrastructure providers, and many others.
I was helping to implement a feedback system for users to send complaints. During pilot testing, we found that a significant percentage of people complained not about what we expected but about "shaky camera," "poor lighting," or gave recommendations on how they would do it if they were filming. As far as I know, they try to respond to everyone as much as possible. It's almost like writing to Santa Claus; if a customer from anywhere in the world wrote, you have to help them.
I was helping to implement a feedback system for users to send complaints. During pilot testing, we found that a significant percentage of people complained not about what we expected but about "shaky camera," "poor lighting," or gave recommendations on how they would do it if they were filming. As far as I know, they try to respond to everyone as much as possible. It's almost like writing to Santa Claus; if a customer from anywhere in the world wrote, you have to help them.
The industry is conservative, but sometimes they ask for strange things
I often have to implement unconventional solutions for clients. The industry is, on one hand, extremely conservative with old but reliable PHP code at the core of the system. On the other, it can be tightly integrated with a modern stack and constantly changing requirements.
For instance, I had a task involving the bootstrap of physical servers serving as content distribution points. Each node group contains several hundred thousand files, actively distributed and cached via CDN. The problem arises when there's a sudden acute shortage of capacities, and we need to add another server to the group. The neighbors are already overloaded, and we need to clone terabytes of data from them for the new node. Eventually, we tested using torrent synchronization for balanced content delivery to the new server during bootstrap. I'll tell more about this in upcoming posts.
Then, another project came with the task of researching LLM-transformers with image-to-text capabilities. And there we were, assembling more complex cascades for the client from systems for automatic frame description, translation, tagging, and other things that needed to integrate with legacy systems.
For instance, I had a task involving the bootstrap of physical servers serving as content distribution points. Each node group contains several hundred thousand files, actively distributed and cached via CDN. The problem arises when there's a sudden acute shortage of capacities, and we need to add another server to the group. The neighbors are already overloaded, and we need to clone terabytes of data from them for the new node. Eventually, we tested using torrent synchronization for balanced content delivery to the new server during bootstrap. I'll tell more about this in upcoming posts.
Then, another project came with the task of researching LLM-transformers with image-to-text capabilities. And there we were, assembling more complex cascades for the client from systems for automatic frame description, translation, tagging, and other things that needed to integrate with legacy systems.
DevOps don't deal with content. Almost.

Some see only the scrolling lines of deployment configuration and running symbols. We see a woman in red. Or something else.
Generally, the tasks of our group are almost not directly related to the content itself. Several monitors, one with an Ansible configuration repository, another with a console setting up Hashicorp Vault integration with Terraform.
It gets more interesting when the task involves working directly with the content. Client’s preview screenshots were initially processed with relatively simple OpenCV using Haar cascades. As volumes grew, we decided to move to more advanced automatic processing of screenshots with rejection, cropping, and sharpening on GPUs with neural networks. I was amazed at how rich people's imagination and tastes are when I was compiling a test dataset of several thousand images. But now, the screenshots are beautiful.
It gets more interesting when the task involves working directly with the content. Client’s preview screenshots were initially processed with relatively simple OpenCV using Haar cascades. As volumes grew, we decided to move to more advanced automatic processing of screenshots with rejection, cropping, and sharpening on GPUs with neural networks. I was amazed at how rich people's imagination and tastes are when I was compiling a test dataset of several thousand images. But now, the screenshots are beautiful.
Your provider can suddenly disconnect you
Now we work with many clients from different fields. But our adult background taught us healthy paranoia. Due to the nature of our clients' business, we're accustomed to the fact that any IP address can be seized, domains redelegated, and infrastructure disconnected from the network within hours. Naturally, all such businesses comply to the fullest with all restrictions and laws of both the region of registration and the location of data centers.
It was hard for me to get used to the idea that a complaint about a client's content had to be addressed within a matter of hours. There you are, leisurely dissecting a poorly described Go module, and suddenly, the monitoring cheerfully reports that a piece of your cluster is gone. And in your email, a message from the provider like "dear customer, for obscure reasons, under clause 184.a and yesterday's policy update, your contract is suspended."
After years of such experiences, we've shifted to a zero-trust concept towards service providers. The service must continue to work despite the banning of domain names in CloudFlare, IP address blockades, full lockdown of rented capacities, and other actions by providers. The infrastructure-as-a-code approach allows for both rapid deployment of production capacities with multiple providers and emergency migration to pre-prepared temporary DRP sites. Initial architectural design with task duplication among several providers also helps.
From time to time, we conduct rehearsals and beautifully break something at the most crucial point. If everything is designed correctly, not a single Jorge Mario from Argentina should notice a degradation in service quality during the switch. It's about social responsibility, after all.
It was hard for me to get used to the idea that a complaint about a client's content had to be addressed within a matter of hours. There you are, leisurely dissecting a poorly described Go module, and suddenly, the monitoring cheerfully reports that a piece of your cluster is gone. And in your email, a message from the provider like "dear customer, for obscure reasons, under clause 184.a and yesterday's policy update, your contract is suspended."
After years of such experiences, we've shifted to a zero-trust concept towards service providers. The service must continue to work despite the banning of domain names in CloudFlare, IP address blockades, full lockdown of rented capacities, and other actions by providers. The infrastructure-as-a-code approach allows for both rapid deployment of production capacities with multiple providers and emergency migration to pre-prepared temporary DRP sites. Initial architectural design with task duplication among several providers also helps.
From time to time, we conduct rehearsals and beautifully break something at the most crucial point. If everything is designed correctly, not a single Jorge Mario from Argentina should notice a degradation in service quality during the switch. It's about social responsibility, after all.
Archaeology is normal
There's an approach in business with unpleasant consequences: "let's burn everything and build something fashionable and beautiful in Kubernetes." From my experience, this, along with "let's move everything to the cloud," often leads to ambiguous results. For example, I know at least one company that decided to save on server rental and DBA by abandoning the "outdated" approach in favor of AWS. Now, they spend a five-figure sum monthly just on cloud capacities, without any notable increase in reliability or cost-effectiveness.
We tend to preserve what brings in money for the business, even if it looks like a fossil amid the modern stack. I was involved in a task to transfer manually configured services to Ansible/Terraform/Packer, and my colleague and I stumbled upon a strange binary in pure C, silently churning without outputting logs. There were no source codes, but there were vague memories from the customer's old-timers that it was something very important. We agreed to simulate a short-term service failure. As soon as the binary stopped, all metrics screamed of a sudden drop in load, as it turned out, it managed all the advertising traffic on some platform.
It turned out that this low-level creation of a mad genius had already been attempted to be transferred to a more modern stack. It ended up working ten times slower and consuming several times more resources. We decided to leave it as is. Automated the creation of nodes, set up several instances for resilience, documented it with DRP, and left a warning for future generations: "Hazard, do not touch!"
A black legacy box. Buzzing, working, making money.
We tend to preserve what brings in money for the business, even if it looks like a fossil amid the modern stack. I was involved in a task to transfer manually configured services to Ansible/Terraform/Packer, and my colleague and I stumbled upon a strange binary in pure C, silently churning without outputting logs. There were no source codes, but there were vague memories from the customer's old-timers that it was something very important. We agreed to simulate a short-term service failure. As soon as the binary stopped, all metrics screamed of a sudden drop in load, as it turned out, it managed all the advertising traffic on some platform.
It turned out that this low-level creation of a mad genius had already been attempted to be transferred to a more modern stack. It ended up working ten times slower and consuming several times more resources. We decided to leave it as is. Automated the creation of nodes, set up several instances for resilience, documented it with DRP, and left a warning for future generations: "Hazard, do not touch!"
A black legacy box. Buzzing, working, making money.
Changing professions could be challenging
Changing professions is always hard. Despite what numerous courses may say, it takes years to become a professional in a new field. In the first years, you'll need to learn three times more intensely than others who have been developing the same skills all along.
This doesn't mean that your previous experience is useless. Decorated half your house with humidity sensors, temperature gauges, and other automation, aggregating all logs? You'll find it much easier to understand RabbitMQ in a work situation. Analyzed large volumes of raw data for hidden correlations in the scientific field? In IT, you'll be handed no less data to analyze. All my colleagues are amazing, talented people with the most diverse backgrounds and hobbies. The main thing is that work tasks feel like the next challenge and make your eyes shine.
So, changing professions is tough but fun. Especially when you tell your new company about your career path from medicine and science to the bloody enterprise and beyond. At this point, I usually pause significantly and leisurely sip tea while those around try to keep a straight face. After a couple of minutes, timid requests for an autograph from the famous astronaut Johnny Sins usually start from the female part of the audience.
So yes - I like this new direction. Millions of visitors rushing in, dragging petabytes of video. Kind search bots that create loads and must be tolerated. Nasty Asian bots trying to clone content and parasitize on the client's resources. Very unpleasant people who arrange DDoS attacks, hitting the most painful parts, causing backend overload.
Our team also decided to move on and change our narrow profile to help other clients make their architecture more transparent and reduce their technical debt. Our accumulated experience allows us to.
So, if you need an audit and want to entrust us with the care of your infrastructure — drop by here. We'll help. And I'll return a bit later to tell you about the interesting things we're building at work.
This doesn't mean that your previous experience is useless. Decorated half your house with humidity sensors, temperature gauges, and other automation, aggregating all logs? You'll find it much easier to understand RabbitMQ in a work situation. Analyzed large volumes of raw data for hidden correlations in the scientific field? In IT, you'll be handed no less data to analyze. All my colleagues are amazing, talented people with the most diverse backgrounds and hobbies. The main thing is that work tasks feel like the next challenge and make your eyes shine.
So, changing professions is tough but fun. Especially when you tell your new company about your career path from medicine and science to the bloody enterprise and beyond. At this point, I usually pause significantly and leisurely sip tea while those around try to keep a straight face. After a couple of minutes, timid requests for an autograph from the famous astronaut Johnny Sins usually start from the female part of the audience.
So yes - I like this new direction. Millions of visitors rushing in, dragging petabytes of video. Kind search bots that create loads and must be tolerated. Nasty Asian bots trying to clone content and parasitize on the client's resources. Very unpleasant people who arrange DDoS attacks, hitting the most painful parts, causing backend overload.
Our team also decided to move on and change our narrow profile to help other clients make their architecture more transparent and reduce their technical debt. Our accumulated experience allows us to.
So, if you need an audit and want to entrust us with the care of your infrastructure — drop by here. We'll help. And I'll return a bit later to tell you about the interesting things we're building at work.

Ivan Gumeniuk
DevOps Engineer, Security Expert